.png?width=337&height=96&name=Logo%20(1).png)
.png.png?height=200&name=Blog%20Cover%20-%20Prophy%20Joins%20Silverchair%20Universe_%E2%80%A8AI%20Reviewer%20Matching%20in%20ScholarOne%20(1).png.png)
Prophy announced its integration with ScholarOne Manuscripts through the Silverchair Universe...
Finding peer reviewers used to mean weeks of manual searching through academic networks and hoping your memory served you well under deadline pressure. At Prophy, we've engineered a recommendation engine that processes manuscripts and matches them to relevant experts from our database of 87 million researcher profiles in seconds.

But how does this technical leap actually work? Our CTO recently walked us through the intricate process that powers our Referee Finder. Here's what happens behind the scenes.
From PDF Upload to Semantic Understanding
The journey begins when you submit a manuscript through one of two pathways: direct integration with editorial management systems or manual PDF upload through our interface. While these entry points differ, they converge into the same sophisticated analysis pipeline.
"In both cases the start is pretty different, but everything that happens after that is very similar," explains CTO Vsevolod Solovyov.
Cracking the PDF Challenge
Here's our first major hurdle: PDFs weren't designed for machine reading. They're visual documents built for human eyes and printing, not algorithmic analysis.
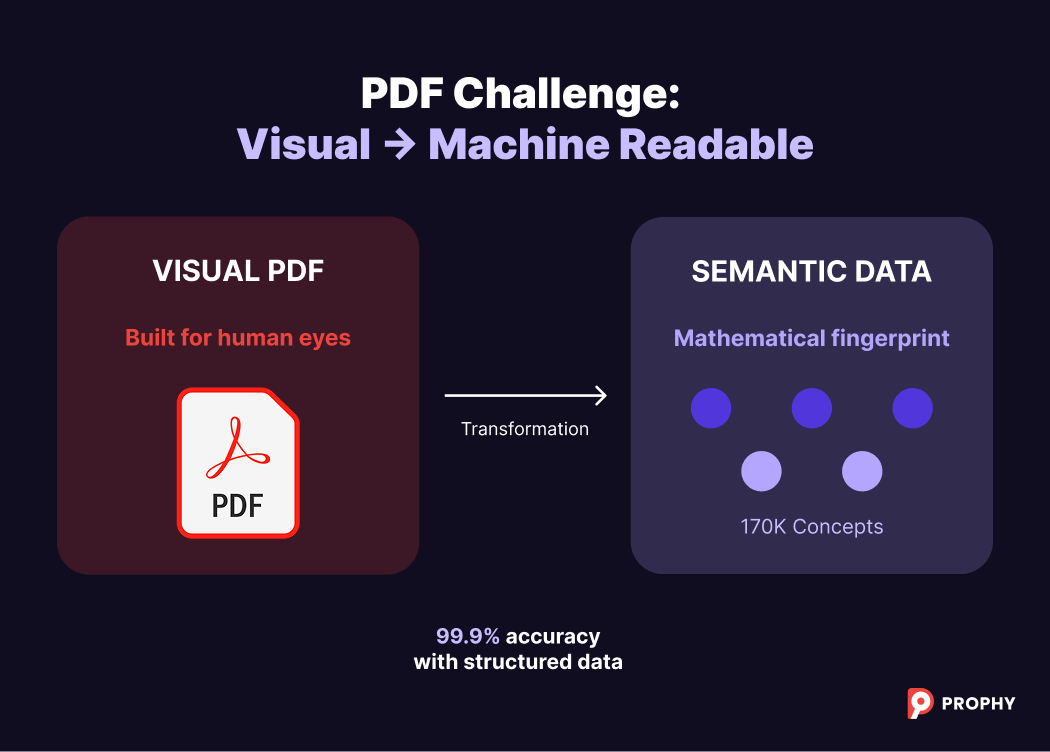
Our specialized extraction tools identify and separate abstracts, full text, references, author information, and affiliations from this format. When manuscripts arrive through editorial systems, we receive structured metadata that dramatically improves accuracy.
"If you just work from the PDF, I would say it's like 90% reliable. But if we have structured information, then it's much, much more reliable, like 99.9% reliable," Solovyov notes.
Creating Mathematical Meaning
Once parsed, we extract scientific concepts and transform the text into a semantic vector - essentially a mathematical fingerprint of the manuscript's meaning. This draws from our ontology of over 170,000 scientific concepts, capturing everything from regional spelling variations to field-specific terminology.
We also link the manuscript's references to existing articles in our database. When authors cite their own work, this creates valuable signals for both conflict detection and expertise validation.
The Complex Art of Author Disambiguation
Now comes the sophisticated challenge: linking manuscript authors to their existing profiles in our database. This process proves far more complex than expected.
"There are like just on a couple of orders of magnitude more ways of how you can match incorrectly author's profile, comparing to just article to reference linking," Solovyov explains.
The ORCID Reliability Problem
ORCID identifiers should solve author identification - they're designed as unique researcher IDs. In practice, approximately 3% of all ORCIDs submitted to journals contain errors. For prolific researchers with 50+ publications, the probability of at least one incorrect ORCID becomes substantial.
"Surprisingly enough, there are less errors with email than with ORCID," notes Solovyov. Email addresses prove more reliable because they're human-readable - mismatches become immediately apparent since emails typically contain the author's name.
Multi-Signal Detection
We solve this by combining multiple evidence sources:
- ORCID identifiers when available and cross-validated
- Email patterns that often prove more reliable than expected
- Co-authorship histories revealing collaboration patterns
- Self-citation patterns where researchers reference their own work
- Institutional affiliations providing geographical context

This detective work enables comprehensive conflict of interest detection beyond just current affiliations, identifying co-authorship conflicts from our database of 178 million papers.
The Ranking Philosophy: Pure Expertise Over Everything
Here's where our approach diverges from expectation. Instead of complex algorithms weighing dozens of factors, we chose radical simplicity.
Semantic Similarity as the Single Truth
"Almost the only one that we take into account when we calculate our score is just the semantic similarity of the document with already published articles,"
Solovyov emphasizes.
We don't boost scores based on institutional prestige, network connections, or career stage. The score reflects expertise, period.
Context Through Filtering, Not Manipulation
Consider the practical reality: a senior professor might review a €5 million grant proposal but won't review for a small journal. Junior researchers perfect for that journal review might not suit major grant evaluations.
"That's why practically only their expertise goes into a score. Everything else is for filtering,"
explains our CTO.
Users can filter by country, gender, career stage, h-index, and recent publications. But these preferences don't manipulate expertise scores - they narrow the candidate pool while keeping measurement pure.

Real-Time Processing at Massive Scale
Processing millions of potential matches in seconds requires serious infrastructure evolution. Our typical response time is around 5 seconds after PDF parsing, but achieving this demanded architectural transformation.
The Infrastructure Journey
We previously ran separate systems for full-text search, filtering, and semantic similarity, requiring multiple database round trips to gather ranking information.
"A couple of years ago we moved to other architecture, and now we have our search engine that handles all of that," Solovyov explains.
This unified, distributed system processes similarity, filtering, and ranking in single requests while scaling across multiple servers instead of single-machine bottlenecks.
Hardware Meets Software
Traditional spinning drives handle about 100 random queries per second. For 1,000 queries in a 50GB table, that's 10 seconds just for disk access. We use NVMe solid-state drives handling tens of thousands of queries per second, plus sufficient RAM to cache critical data and eliminate disk access for frequent operations.
Solving Extreme Edge Cases
Some manuscripts present extraordinary challenges. Papers from large collaborations like CERN's Atlas detector can have 2,500+ authors. Calculating conflicts of interest for such papers previously required processing millions of potential conflicts - a 20-minute operation that would timeout and potentially crash our service.
"Just yesterday we fixed a corner case... now it takes like a couple of seconds," notes Solovyov. The solution involved intelligent limits: instead of processing unlimited conflicts, we cap meaningful calculations while maintaining comprehensive coverage.
For normal manuscripts, the system processes recommendations in roughly 0.2 seconds.
Engineering Philosophy Meets Academic Reality
Our recommendation engine represents years of architectural refinement focused on delivering accurate expert matches faster than manual methods while maintaining scientific integrity.
The technical stack combines semantic analysis, distributed computing, and intelligent caching to transform a weeks-long manual process into a seconds-long automated operation. But the real innovation lies in our scoring philosophy - prioritizing pure expertise while leaving context-specific factors as user-controlled filters.
This approach serves clients across funding agencies and publishers who need different expert types for different contexts. The same engine identifies reviewers for major grant proposals and finds experts for emerging journals, with users controlling experience through filtering rather than algorithmic manipulation.
We've turned one of academia's most time-intensive processes into a rapid, data-driven operation that still respects the human elements of scientific evaluation.
Ready to experience this recommendation engine firsthand? Request a demo of Prophy's Referee Finder to see how these technical capabilities streamline your peer review process.


.png?height=200&name=Blog%20Cover%20-%20How%20Our%20Similarity%20Algorithm%20Solves%20the%20Reviewer%20Relevance%20Problem%20(1).png)