.png?width=337&height=96&name=Logo%20(1).png)


Introduction: The AI Revolution in Scientific Peer Review Scientific publishing stands at a...
Managing peer review processes efficiently while maintaining editorial quality is one of the biggest challenges facing academic publishers today. As manuscript volumes grow and reviewer fatigue increases, the need for seamless integration between peer review tools and editorial management systems has become critical.
We’ve spent years building integrations between Prophy’s referee finder and various editorial platforms. Here’s what we learned about making these integrations actually work for busy editorial teams—including the failures, the breakthroughs, and the technical realities that no one talks about in conference presentations.
The Real Cost of Manual Peer Review Processes
Before we dive into technical solutions, let’s examine what manual peer review management actually costs your organization.
Picture this: Your editor opens a manuscript on quantum computing applications. They know the field needs experts in both quantum mechanics and software engineering, but drawing from memory under deadline pressure? That’s where things get complicated.
When editors handle referee selection manually, they typically spend 2-4 hours per manuscript just identifying qualified reviewers. For a journal processing 200 manuscripts annually, that’s 400-800 hours of senior editorial time. But the hidden costs run deeper—delayed publication timelines, reputation risks from undetected conflicts of interest, and reviewer burnout from irrelevant requests.
This is why integration between peer review tools and editorial workflows isn’t just about convenience—it’s about sustainable publishing operations.
Why Most Publishers Resist Integration (And Why They’re Right)
Here’s what we discovered early on: The biggest barrier to adoption wasn’t our technology—it was workflow disruption.
Think about your typical editor managing dozens of manuscripts weekly. Their workflow is finely tuned: review submissions in their editorial management system, coordinate with authors, track reviewer communications. Now imagine asking them to export each manuscript manually, switch platforms, upload files one by one, manually input author information, then return to their original system with results.
For one manuscript per week? Annoying but manageable. For dozens? Completely unrealistic.
We learned this lesson the hard way. Our initial approach assumed editors would be willing to switch between systems. They weren’t. And they were absolutely right—their time is too valuable for manual system-hopping.
The Architecture Challenge: Building for the Real World
After studying how publishers actually work, we developed what we call a “dual-track integration strategy.” But let me be honest about why this approach emerged—it wasn’t elegant design theory. It was pure necessity.
The editorial management system landscape is fragmented. Some platforms have robust APIs, others barely function as advertised, and many publishers run custom-built systems that would make you weep if you saw the code.
Track 1: Native API Integration
For established systems with existing referee finder APIs, we integrate directly with their infrastructure. When everything goes right—clear documentation, available test environments, reasonable response times—we can complete these integrations in a few days to a week.
When everything goes wrong? Well, let me tell you about our Editorial Manager adventure.
Track 2: Our Universal API Architecture
For everyone else, we built our own three-layer integration system:
Layer 1: Embedded Quick Reference A simple candidate list appears directly in the editorial system. This handles the common scenario where editors know the field but need help remembering specific names. It’s lightweight, requires minimal technical resources, and solves the “tip-of-the-tongue” problem.
Layer 2: Context-Preserved Deep Access One-click access to our full interface from within the editorial system, complete with filters, explanations, and detailed analysis. The key insight here: maintain manuscript context so editors never lose their place in the workflow.
Layer 3: Seamless Workflow Completion Select referees in our system, click to approve, and they’re automatically sent back to the editorial system via API hooks. This eliminates the manual data entry that kills adoption.
This layered approach lets publishers choose their integration depth based on technical resources and workflow preferences. It’s not theoretically perfect, but it works in practice.
The Backwards Compatibility Nightmare (And How We Solved It)
As we evolved our API, we hit a classic software development dilemma: How do you improve your system without breaking existing integrations?
We learned this lesson by observing what happened to NumPy when they broke backwards compatibility moving from version 2 to 3. Adoption stalled for years because most users stayed on version 2 rather than deal with migration pain. We weren’t about to repeat that mistake.
Our solution follows three non-negotiable principles:
Never Break Existing Functionality New parameters are always optional with sensible defaults. If your integration worked yesterday, it works today. Period.
Support Parallel Parameter Names When we rename parameters for clarity, we accept both old and new names. New integrations get clearer documentation while existing integrations continue working unchanged.
Opt-In Behavior Changes Any changes to default behavior are controlled by new optional parameters. This lets clients adopt improvements on their timeline, not ours.
This approach has maintained 100% backwards compatibility across two years of continuous API improvements. But I’ll be honest—it’s not always elegant. Sometimes our code looks like an archaeological dig with layers of parameter handling. But it works, and our clients trust us because of it.
The Editorial Manager Mystery: A Debugging Detective Story
Let me walk you through our most challenging integration—one that taught us the value of building comprehensive debugging tools.
We were integrating with Aries Editorial Manager, a well-known system that provided PDF documentation for their API. Everything looked straightforward until we started testing. Every single request returned a “timeout” error.
But here’s the thing—our API was responding in under one second. Even when we created a test endpoint that returned a static response instantly, they reported timeouts. It made no sense.
The traditional debugging approach would have been painful: submit a support ticket, wait for their development cycle (which turned out to be 6 weeks), get a one-line response about a specific field, fix that, hit another error, repeat. We could have been debugging for months.
Instead, our developer Andriy created what I consider a stroke of genius—a dynamic response modification system for real-time debugging.
The Binary Search Breakthrough
Here’s how we solved it: We found a document that triggered the timeout, then modified our API response on-the-fly to return only half the data. Still timing out? Try one quarter. Continue until we isolated the exact field causing issues.
This binary search approach—it’s the same principle computer scientists use for efficiently searching sorted lists—let us identify problematic fields in hours instead of weeks.
What we discovered was fascinating and frustrating: Multiple fields marked as “optional” in their PDF documentation were actually required on their end. Worse, their system was catching various errors and re-throwing them all as “timeout” messages. So a null value in what should have been an optional field appeared as a timeout error.
The lesson? Build debugging visibility into your integrations from day one. When things go wrong—and they will—you need to see exactly what’s happening.
The Journal Name Chaos Problem
Here’s a challenge no one warns you about: journal name consistency. Or rather, the complete lack thereof.
When an editorial management system serves hundreds of publishers with thousands of journals, the same journal might appear in API calls as:
- “Journal of Applied Physics”
- “J. Appl. Phys.”
- “Journal of Applied Physics & Engineering”
- “Jnl Applied Physics”
Sometimes they use ampersands, sometimes “and.” Sometimes abbreviations, sometimes full names. Sometimes they send us the full name but their API delivers the abbreviation. It’s chaos.
Our initial approach required manual mapping tables for each journal. The workflow was painful:
- Publisher requests journal activation
- We manually add journal to our database
- First API request fails due to name mismatch
- We debug the exact name format used
- We update our mapping table
- Repeat for each new journal
This process took days or weeks per journal. For a publisher with dozens of journals, it was unworkable.
The Self-Service Solution That Changed Everything
We replaced this entire manual process with what we call “journal claiming.”
When an unknown journal makes its first API request, instead of returning an error, we return a special response containing a “Test Author” entry with a secure “Claim Journal” link.
The account manager clicks this link, confirms journal ownership through our verification process, and the system automatically maps the journal’s internal name format to their organization. It’s secured with cryptographically signed, single-use tokens—they work once and then expire.
This reduced journal activation time from weeks to under five minutes. More importantly, it eliminated the frustrating back-and-forth that made our integrations feel broken even when they were working perfectly.
The Integration Speed Spectrum: A Tale of Three Publishers
Working with diverse publishers taught us that technical competence varies dramatically across the industry. Let me give you three real examples that illustrate this spectrum:
The Speed Champions: A New Zealand publisher. We had 11-12 hour time zone differences, so we scheduled calls at 8 AM—which meant 8 AM for one of us and 8 PM for the other. Two calls. Three days. Full three-layer integration working perfectly. Their developer was so competent it was almost unfair to our other integration experiences.
The Silent Professionals: A crystallography publisher with a custom editorial management system. We sent them our API documentation and heard… nothing. No calls, no questions, no status updates. Then we noticed successful API requests appearing in our logs. They’d implemented everything without a single support interaction. We still don’t know exactly how long it took them, but it was fast and flawless.
The Challenging Cases: Some integrations required extensive support, custom error handling, and multiple debugging cycles to achieve basic functionality. These weren’t necessarily less competent teams—sometimes they were dealing with legacy systems, resource constraints, or organizational challenges that made everything harder.
This performance spectrum reinforced our decision to provide multiple integration paths and comprehensive self-service resources. You can’t predict which type of team you’re working with until you’re in the middle of it.
Building Integration Debugging That Actually Works
One of our most valuable features isn’t visible to end users—it’s the comprehensive logging system we built for integration debugging.
When an editorial management system sends us a request, both sides can see exactly what happened:
- The exact request sent (timestamped to the millisecond)
- Our complete response
- Any errors or system status information
This visibility proved essential during our Editorial Manager debugging adventure, but it’s valuable for routine troubleshooting too. When a publisher reports that “nothing is working,” we can quickly identify whether it’s a configuration issue, a data format problem, or something else entirely.
The key insight: In B2B integrations, debugging transparency builds trust. When both sides can see exactly what’s happening, finger-pointing disappears and collaborative problem-solving begins.
Current Integration Landscape and What We’ve Learned
Today, we’re actively integrated with several major editorial management systems:
Aries Editorial Manager: Full three-layer integration (after our debugging adventure)
ScholarOne: Integration in progress
Custom systems: Multiple publishers using our universal API
Rather than building unique solutions for each platform, we’ve standardized on our universal API that handles the majority of use cases while providing platform-specific optimizations where needed.
But here’s what we’ve learned about the integration landscape: The technical challenge isn’t the hardest part. The hardest part is understanding how editorial teams actually work and building solutions that enhance rather than disrupt their workflows.
Planning Your Integration: A Practical Roadmap
If you’re considering peer review tool integration, here’s our recommended approach based on hard-won experience:
Start with Workflow Analysis
Before any technical planning, spend time with your editorial team. Watch how they actually work, not how you think they work. Identify specific pain points and time-consuming manual processes.
Assess Your Technical Reality
- Does your current system support third-party integrations?
- What authentication standards can you implement?
- What manuscript and reviewer data formats does your system use?
- What response times do your editors expect?
Plan for the Integration Spectrum
Different publishers have different technical capabilities. Plan for multiple integration approaches—you might need basic functionality initially with room to grow.
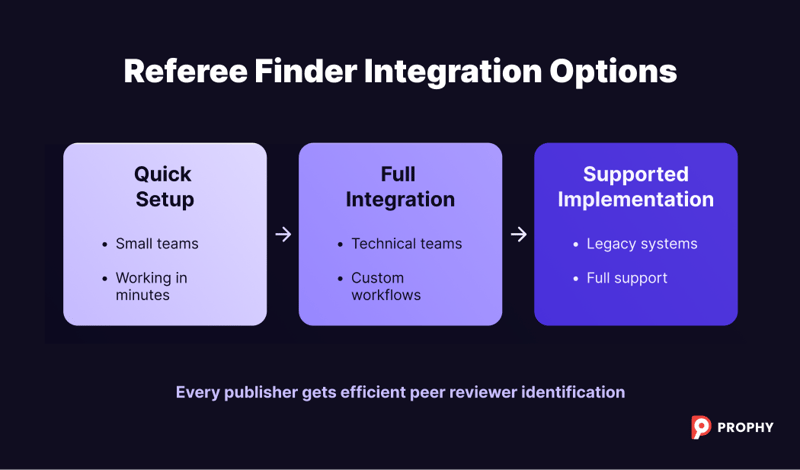
Build in Debugging Visibility
Whatever integration approach you choose, make sure both sides can see what’s happening when things go wrong. Trust me on this one.
The Future of Editorial Integration
As manuscript volumes continue growing and reviewer pools face increasing pressure, seamless integration between editorial management systems and specialized tools becomes essential for sustainable publishing operations.
The most successful integrations we’ve built share common characteristics: they preserve existing editorial workflows, provide immediate value to daily users, and maintain reliable performance under production loads.
But the future isn’t just about technical integration—it’s about workflow evolution. As AI and automation handle more routine tasks, editorial teams can focus on higher-value activities like ensuring review quality and managing complex editorial decisions.
Our goal remains constant: let editors focus on editorial decisions while technology handles the complexity of finding qualified reviewers efficiently and transparently.
The integration challenge isn’t just about connecting systems—it’s about understanding workflows, anticipating problems, and building solutions that work reliably in the real world. Every integration teaches us something new about how publishers operate and how we can serve them better.
Ready to explore peer review integration for your editorial management system? Our technical team can assess your current workflow and recommend the optimal integration approach for your organization. Contact us.


